自最新的通义千问大模型Qwen3发布以来,凭借其优秀的模型表现,备受关注。在当前AI大模型快速发展的时代,AMD AI生态伙伴模优优科技继成功实现DeepSeek V3大模型的AI PC优化部署后,第一时间成功将全尺寸Qwen3-235B模型优化,部署到基于AMD锐龙 AI Max+ 395处理器的mini PC上,推理速度达到14tokens/s。
AMD 锐龙 AI Max+ 395:为大模型量身打造的终端算力
AMD 锐龙 AI Max+ 395处理器拥有16核32线程、最高加速时钟频率5.1GHz,集成了基于RDNA 3.5架构的40个计算单元的Radeon 8060S GPU,以及高达50+ TOPS 的”XDNA 2″架构 NPU。

模优优科技的技术团队充分利用了AMD锐龙AI Max+ 395的独特架构特性,特别是其统一内存设计和高达96GB的可分配显存,通过定制化的内存调度策略和深度量化优化,成功克服了大模型在端侧部署的内存和计算瓶颈,使全尺寸Qwen3-253B模型能够在AI PC上流畅运行。
Qwen3全尺寸模型端侧高效部署
模优优科技凭借自身深厚的技术积累,将这一全尺寸模型成功优化并部署到采用AMD锐龙 AI Max+ 395处理器的惠普和华硕笔记本电脑,以及极摩客的mini PC上。而在极摩客的 EVO-X2 mini PC上,推理速度达到14tokens/s,实现了端侧设备上大模型高效部署的创新。

值得一提的是,模优优科技基于创新的混合量化技术和策略,在保证推理速度的同时,也能保证Qwen3-235B在mini PC端侧部署的推理精度,相较于传统常见的端侧Q4量化32B,70B模型提升明显,以及对比同尺寸的Q8量化Qwen3模型,精度接近。
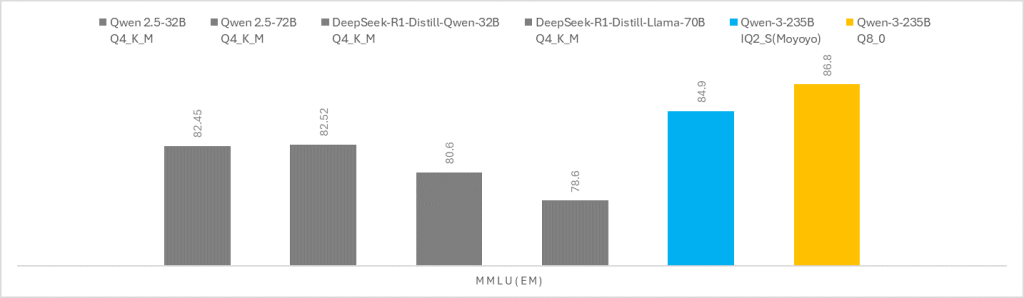
(该测试数据来源于模优优技术团队)
“我们的异构加速方案彻底改变了大模型部署的成本结构与性能边界,使企业和个人用户都能在本地设备上体验全尺寸Qwen3-253B带来的强大AI能力。”模优优科技创始人兼CEO王言治博士表示,”14tokens/s的推理速度意味着用户可以获得流畅的对话体验,而无需依赖云端资源。”
模优优异构加速方案的技术亮点
模优优科技基于对AMD平台的深度优化,为Qwen3-253B模型部署提供了全面的异构加速解决方案:
- 精细量化与内存优化:针对Qwen3模型的混合专家架构特性,模优优团队采用了差异化量化策略,对关键层和路由专家进行精细量化处理,在保持模型精度的前提下,显著降低了内存需求。
- 多硬件协同加速:方案充分整合了GPU和CPU资源,实现了硬件资源的高效利用,推理速度达到14tokens/s,为用户提供媲美云端的对话体验。
- 动态计算调度:针对Qwen3模型支持思考模式和非思考模式切换的特性,模优优技术团队开发了自适应计算调度系统,根据任务复杂度动态分配计算资源,实现性能与体验的最优平衡。
对企业和个人用户的价值
- 隐私安全保障:大模型完全在本地运行,敏感数据无需上传云端,从根本上解决数据安全问题。
- 成本显著降低:相比云端API调用,本地部署可大幅降低长期使用成本,尤其适合高频率使用场景。
- 离线使用能力:无需依赖网络连接,即可随时随地获得强大的AI助手支持。
- 解决方案可扩展:模优优的异构加速技术可应用于更广泛的硬件平台,为不同行业场景提供定制化解决方案。
未来展望
随着Qwen3系列模型的发布和端侧部署能力的突破,模优优科技与AMD将持续合作,推动AI解决方案在更多端侧场景化应用落地,进一步释放大模型在终端的应用潜力。


